Tencent Hunyuan Image 2.0 generates images in real time
Writer: | Editor: Zhang Zhiqing | From: Shenzhen Daily | Updated: 2025-05-20
Tencent Hunyuan recently released the Hunyuan Image 2.0 model, which features a highly compressed image codec and a brand-new diffusion architecture that enables the real-time generation of high-quality images.
Currently, the biggest issue with most text-to-image models is the long generation time, with most requiring at least 5-10 seconds to produce a single image. Moreover, it typically takes users multiple attempts to get a satisfactory result. With the Hunyuan Image 2.0 model, users can see real-time changes to the image as they gradually alter the prompt.
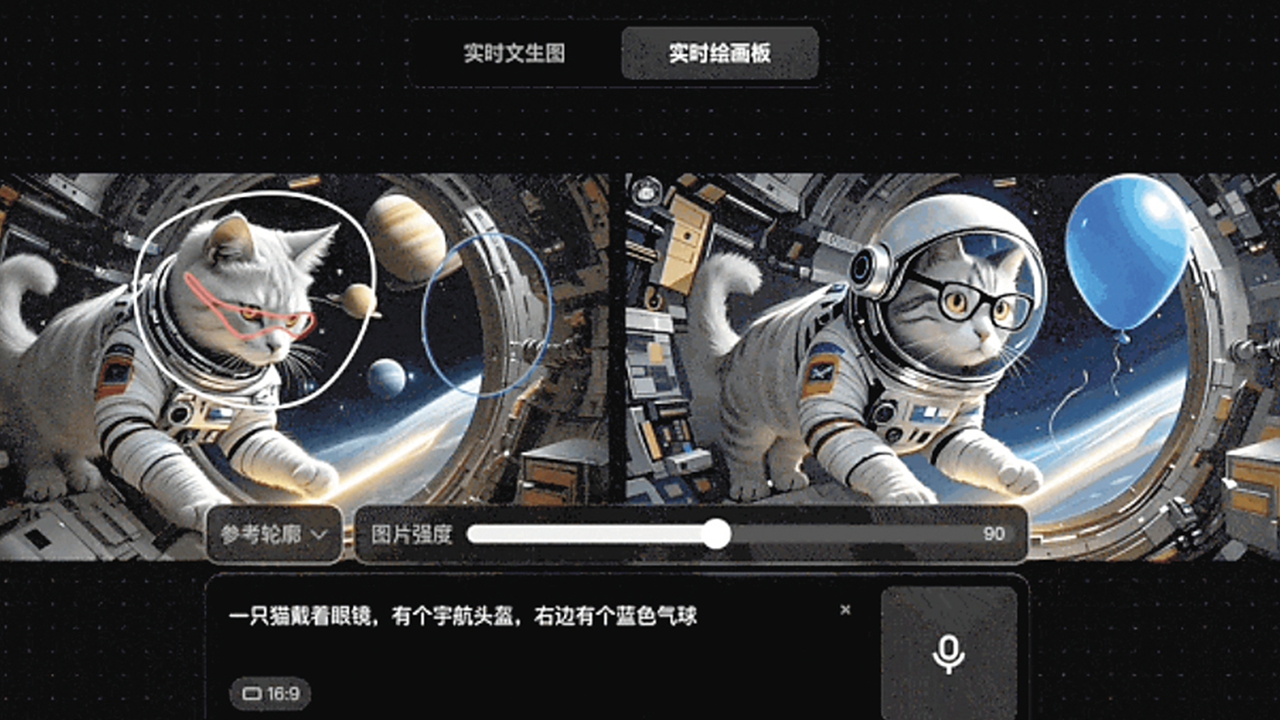
A screenshot of Tencent Hunyuan Image 2.0 generating an image on its drawing board interface.
Testing of Hunyuan Image 2.0 shows that it has a strong ability to follow text instructions and can modify image content in real time. For professional designers, its drawing board feature can generate various styles and adjust lighting and shadows, all with immediate visual feedback.
However, the multi-layer fusion function in the dual-canvas linkage setup is somewhat slower than real-time text-to-image generation and requires multiple prompt adjustments to achieve good results.
As for style presentation, sometimes the generated image does not match users’ prompts exactly, requiring more detailed prompts or multiple rounds of prompt refinement. However, unlike other models, adjustments can still be seen immediately.
Users can register on Tencent Hunyuan’s official website (hunyuan.tencent.com) to experience this tool.
Besides directly generating images from text, Hunyuan Image 2.0 also supports uploading images to generate new images. Different from traditional image generation models, Hunyuan Image 2.0 can extract subject or contour features from original images and fuse them with text instructions to create new images.
For example, if a user selects the subject mode to modify an image of a pet, the pet is extracted, allowing the user to place it on grass or another background. If the contour mode is chosen, the model automatically extracts the pet’s outline, enabling users to input prompts for creative tasks such as coloring.